More than 58% of property management companies worldwide now use digital software solutions, with over 62% of all deployments running on cloud-based platforms as of 2026. For buyers, sellers, investors, and agents, that shift has produced a generation of top real estate apps that handle everything from property search and mortgage calculation to lease management and portfolio monitoring in a single interface.
Choosing the right app depends on your role and what problem you need to solve. A residential buyer needs different tools than a commercial investor or a property manager overseeing 200 units. This guide covers 10 platforms built for different segments of the market, what each one does well, and where its limits are.
At Hudasoft, we build custom real estate platforms for agencies, brokers, and property investors. The perspective in this guide reflects that experience.
Quick Comparison of The 10 Best Real Estate Apps in 2026
Use the table below to compare each top real estate app based on what it actually does best.
| App | Best For | Pricing | Platform | Key Strength | 2026 Update |
|---|---|---|---|---|---|
| Zillow | Buyers and sellers browsing residential listings | Free | iOS, Android, Web | Largest listing database in the U.S., Zestimate AVM | Doubling down on housing super app strategy, integrating search, financing, and touring |
| Redfin | Buyers wanting real-time MLS data and lower commissions | Free to use, 1% to 1.5% seller commission | iOS, Android, Web | Real-time MLS sync, lower agent fees than traditional brokerages | Now receives Compass private exclusives and coming soon listings not visible on Zillow |
| Qarya | Owned by Zillow Group, hyperlocal data remains the strongest feature | Custom pricing, built by Hudasoft | iOS, Android | Centralized resident management, utilities tracking, payments, and service requests in one platform | Property developers and community operators need unified resident management |
| Trulia | Buyers focused on neighborhood lifestyle and safety | Free | iOS, Android, Web | Crime data, school ratings, and resident reviews by neighborhood | Building-specific search filters unique to the New York City market |
| StreetEasy | NYC renters and buyers | Free | iOS, Android, Web | Free to request an offer, variable service fee | Dominant in NYC with 180 million annual visits |
| Opendoor | Sellers wanting instant cash offers without listing | Free to request offer, variable service fee | iOS, Android, Web | Instant cash offer and fully digital closing | Opendoor Checkout now live in 40 states with mortgage preapproval and digital closing tools |
| Compass | Agents managing listings and client pipelines | Opendoor Checkout is now live in 40 states with mortgage preapproval and digital closing tools | iOS, Android, Web | AI-powered agent tools and deal pipeline tracking | Buyers want search and financing in one app |
| Roofstock | Remote single-family rental investors | Free to browse, 0.5% buyer fee | iOS, Android, Web | Vetted turnkey rental properties with income data pre-loaded | Growing rapidly among non-local investors |
| Realtor.com | Buyers and renters wanting MLS-accurate listings | Free for consumers, RealPro Select for agents | iOS, Android, Web | MLS-direct listing feeds licensed by NAR, highest data accuracy among public portals | Launched Realtor.com+ in January 2026 in partnership with MLS organizations, driving 3.4x the visit share of Homes.com |
| Custom Build | Businesses needing proprietary real estate platforms | Project-based, starting $50,000+ | iOS, Android, Web | Built around your data model and workflow | Right choice when no off-the-shelf app fits your operation |

1. Zillow
Best For: Residential buyers, sellers, and renters searching the U.S. market
Pricing: Free for consumers. Agents pay for Premier Agent placement on a cost-per-lead basis.
Platform: iOS, Android, Web
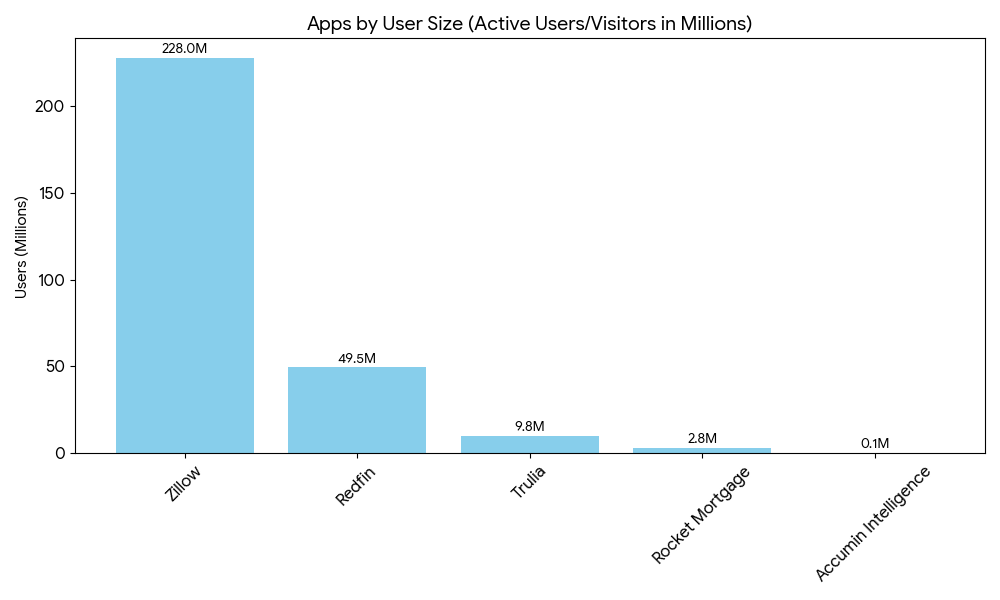
Zillow is the largest real estate marketplace in the U.S. by traffic. In Q4 2025, Zillow reported 221 million average monthly unique users and 2.1 billion visits, with full-year 2025 revenue reaching $2.6 billion, up 16% year over year. Its platform covers property search, Zestimate valuations, 3D home tours, mortgage calculators, and agent matching in one interface.
In 2026, Zillow is focused on integrating search, financing, and touring into a single workflow. The Listing Access Standards policy, introduced in late 2025, means some Compass private exclusives no longer appear on Zillow.
Limitation: Buyers relying only on Zillow may miss over 500,000 Compass listings now syndicated to Redfin. For full market coverage, using both platforms is advisable in competitive markets.
Who Should Skip It: Commercial investors and property managers. Zillow is built for residential use only.
2. Redfin
Best For: Buyers wanting real-time MLS data and sellers looking for lower commission rates than traditional brokerages
Pricing: Free for buyers. Sellers pay 1% to 1.5% commission, compared to the traditional 2.5% to 3% brokerage rate.
Platform: iOS, Android, Web
Redfin attracts approximately 46 million monthly users and generates around $1.03 billion in trailing twelve-month revenue as of early 2026. Its core advantage is real-time MLS integration that surfaces listings faster than most competing platforms, paired with built-in mortgage tools and instant tour scheduling.
In February 2026, Compass announced a partnership with Redfin and Rocket Companies, syndicating over 500,000 private exclusives and coming soon listings to Redfin. This gives Redfin users access to inventory that does not appear on Zillow, which is a meaningful shift in the residential search landscape.
Limitation: Redfin agents handle more clients per agent than traditional brokerages, which means service levels can vary. Coverage is strongest in major U.S. metros and thins in rural and secondary markets.
Who Should Skip It: Commercial real estate professionals and investors needing portfolio-level analytics. Redfin is a residential search and brokerage platform.
3. Qarya
Best For: Property developers and community operators managing residential communities who need rent collection, maintenance, resident communication, and utilities tracking in one platform
Pricing: Custom pricing. Contact Hudasoft to discuss your project requirements.
Platform: iOS, Android
Qarya is a smart community management platform built by Hudasoft for residential community operators. Property managers running operations across spreadsheets, WhatsApp groups, and manual end-of-month reports get a unified dashboard covering every operational dimension of community management.
The platform covers recurring invoices, real-time payment tracking, STC Pay and Mada integration, maintenance ticketing with photo and video uploads, automated assignment and escalation, resident announcements, and NLP-driven request classification. It is built on Flutter for iOS and Android with bilingual Arabic and English support, and reporting through Power BI.
Limitation: Qarya is a custom-built platform, not an off-the-shelf app available on public app stores. It requires a development engagement with Hudasoft and is built around your specific community management workflow.
Who Should Skip It: Individual landlords managing a small number of units who need a lightweight self-serve tool. Qarya is designed for operators managing residential communities at scale.
4. Trulia
Best For: Residential buyers researching neighborhood quality, safety, and lifestyle before committing to a property search
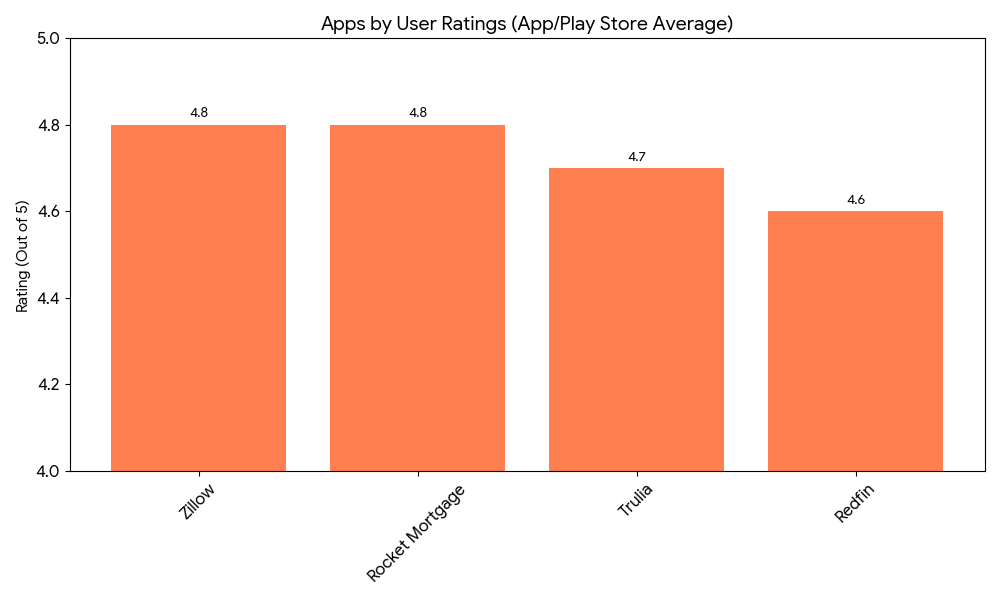
Pricing: Free for consumers. Agents pay for featured listings from $30 per month for one listing up to $200 per month for ten listings.
Platform: iOS, Android, Web
Trulia is the third most visited real estate website in the U.S., owned by Zillow Group since its acquisition in 2015. The platform attracts approximately 19 to 21 million monthly visits. Its focus is neighborhood context rather than listing volume, covering crime maps, school ratings, commute times, resident reviews, and nearby amenities alongside standard property listings.
The Neighborhoods feature lets buyers explore areas through photos, resident-submitted reviews, and color-coded crime and price data. This makes Trulia useful for buyers relocating to an unfamiliar city who need to evaluate areas before shortlisting specific properties.
Limitation: Trulia does not directly provide MLS listings, and listings can sometimes be outdated, with users reporting already-sold properties still appearing as available. Its listing database is smaller than Zillow’s and Redfin’s.
Who Should Skip It: Buyers who already know the neighborhood they want and need the most current listing data. Zillow or Redfin will serve them better for that specific need.
5. StreetEasy
Best For: NYC renters and buyers searching for apartments, condos, and co-ops across the five boroughs
Pricing: Free for consumers. Agents can access the new Agent Advantage program launched in April 2026, with Pro and Signature tiers covering priority search placement, performance analytics, customizable comps reports, and predictive analytics. Pricing for agent tiers is not publicly listed.
Platform: iOS, Android, Web
StreetEasy is a Zillow brand built specifically for the New York City market, covering rentals and sales across Manhattan, Brooklyn, Queens, the Bronx, and Staten Island. Its search filters are built around NYC-specific criteria that national platforms do not support, including building-level searches, doorman availability, walk-up preferences, floor level, and co-op board approval requirements.
The platform publishes monthly NYC market reports covering median asking rents, days on market, and inventory levels by neighborhood, which buyers and renters use to time their searches and negotiate effectively.
Limitation: StreetEasy is exclusively NYC-focused. It has no coverage outside the five boroughs. Buyers and renters in any other U.S. market will find no useful data here.
Who Should Skip It: Anyone searching for real estate outside New York City. For agent-specific tools beyond listing search, our guide on apps for real estate agents covers platforms built for agent productivity nationwide.
6. Opendoor
Best For: Home sellers who prioritize speed and certainty over maximum sale price and want to avoid the traditional listing process
Pricing: Free to request an offer. Opendoor charges a 5% service fee plus typical closing costs of 0.5% to 1%, and deducts repair costs the company determines are necessary before resale.
Platform: iOS, Android, Web
Opendoor is the largest iBuyer in the U.S., purchasing 8,241 homes in 2025 under new CEO Kaz Nejatian, who has named increasing acquisition volume and improving resale turnaround as the company’s 2026 priorities. The platform generates a cash offer within minutes, allows sellers to choose their closing date, and handles the transaction digitally without showings or negotiations.
Opendoor Checkout is now live in 40 states, with mortgage preapproval, buyer protections, and digital closing tools embedded in the platform. The company controls an estimated 67% of the U.S. iBuyer market.
Limitation: Research on 409 Opendoor transactions found the company typically pays about 7.8% below market value at resale, equal to roughly $39,000 less on a $500,000 home. Sellers gain speed and certainty but generally net less than they would through a traditional listing.
Who Should Skip It: Sellers not in a time-sensitive situation. If maximizing sale price is the priority, a traditional agent or MLS listing will produce better financial outcomes in most markets.
7. Compass
Best For: Residential real estate agents managing listings, client pipelines, and transactions through a single platform
Pricing: Compass is not a consumer-facing app. Agents join Compass as a brokerage and access the platform as part of their affiliation. Commission splits vary by market and agent agreement.
Platform: iOS, Android, Web
Compass reported record full-year 2025 revenue of $7.0 billion, up 23.1% year over year, with 21,190 principal agents on the platform and a 96.8% quarterly agent retention rate in Q4 2025. Its platform covers the full agent workflow from first client contact to closing in a single login, covering listings, client communication, deal pipeline, predictive analytics, and title and escrow integration.
Compass One, launched in early 2025, is an all-in-one client dashboard used by agents with approximately 370,000 clients in 2025, giving buyers and sellers real-time transaction visibility. The February 2026 partnership with Redfin and Rocket gives Compass agents access to Redfin’s 2 billion annual visits and an expected 1.2 million leads.
Limitation: Compass is only accessible to agents affiliated with the brokerage. Buyers and sellers cannot use the platform directly. Independent agents or those at other brokerages have no access to Compass tools.
Who Should Skip It: Buyers, sellers, and investors searching for properties. Compass is a brokerage platform for affiliated agents only.
8. Roofstock
Best For: Remote single-family rental investors who want to buy tenant-occupied properties outside their home market without needing to visit in person
Pricing: Free to browse. Roofstock charges buyers a marketplace fee of 0.5% of the contract price or $500, whichever is greater, and sellers a listing fee of 3% of the sale price.
Platform: iOS, Android, Web
Roofstock has facilitated more than $4 billion in investment transactions since its founding in 2015, operating as the leading digital platform for the $4 trillion single-family rental sector. Properties on the platform are independently certified and typically come with tenants already in place, which means investors start collecting rental income from day one.
In January 2026, Roofstock completed the sale of nearly 1,700 single-family rental properties in a strategic portfolio transaction and launched a short-term rental management division through an investment in Casago in May 2025. Each listing includes rental income data, cap rate projections, neighborhood ratings, and property management options. Investors who want deeper portfolio tracking alongside acquisition data will find purpose-built real estate data analytics software more suited for that layer of analysis.
9. Realtor.com
Best For: Buyers and renters wanting MLS-accurate listings with editorial market context, agent matching, and new construction search in one platform
Pricing: Free for consumers. Agents pay for RealPro Select, a premium marketing subscription for brokerages covering enhanced listing exposure, lead tools, and digital marketing services.
Platform: iOS, Android, Web
Realtor.com reported revenue of $143 million in Q2 of fiscal year 2026, a 10% year-over-year increase, driven by premium offerings and audience share gains. Operated by Move, Inc., a News Corp subsidiary, and licensed by the National Association of Realtors, Realtor.com draws its listings directly from MLS feeds, which makes its data among the most accurate available on any public portal.
According to Comscore data cited by Realtor.com CEO Damian Eales, the platform drove 3.4 times the visit share of Homes.com and 2.3 times that of Redfin, while closing more than half the visit share gap with Zillow over the past 18 months. In January 2026, Realtor.com launched Realtor.com+, built in partnership with MLS organizations to strengthen data accuracy, agent attribution, and AI-driven member tools.
Limitation: Average monthly unique users declined 6.5% year-over-year to 72 million in a recent quarter, and lead volume also fell 9% for fiscal year 2025, indicating the platform is reaching fewer users despite growing revenue per lead. It covers residential properties only with no commercial data.
Who Should Skip It: Commercial investors, property managers, and anyone needing portfolio-level analytics or off-market deal sourcing. Realtor.com is a consumer-facing residential search platform.
10. Custom Real Estate Platform
Best For: Real estate agencies, brokers, property developers, and investors whose workflows do not fit any off-the-shelf app
Pricing: Project-based. Custom real estate platforms built by Hudasoft start at $50,000 and scale based on scope, integrations, and ongoing maintenance requirements.
Platform: iOS, Android, Web
Off-the-shelf apps serve the broadest possible user base. When your portfolio covers multiple asset classes, your data sits across disconnected systems, or your reporting logic is proprietary, no amount of configuration fixes that mismatch.
A custom platform is built around how your team works. Property data, financial modeling, CRM, and operational reporting sit in one place, structured around your data model rather than a vendor’s.
Teams deciding whether to build or buy should first audit what existing tools can cover. A real estate CRM for small teams is a practical starting point before committing to a custom build.
Limitation: Custom development requires more upfront investment than activating a SaaS subscription. It is the right answer when your workflow is genuinely unique, not when an existing tool needs better configuration.
Who Should Skip It: Individual landlords, solo agents, and small teams whose needs are well served by any of the nine platforms above.
What the Best Real Estate Apps Have in Common
The top real estate apps on this list serve different users and solve different problems. A few patterns hold across all of them.
Data Accuracy Matters More Than Feature Count
Zillow, Redfin, and Realtor.com all invested heavily in MLS data quality before adding features. Platforms with inaccurate or stale listings lose users fast, regardless of how well the rest of the product works.
Mobile Is the Product, Not a Feature
Every platform on this list generates more traffic from mobile than from desktop. Apps built desktop-first and ported to mobile consistently underperform against those built mobile-first from the start.
Automation Reduces Friction at the Point of Decision
Opendoor removed showings. Roofstock removed in-person visits. Compass removed multi-tool switching for agents. Each platform identified the highest-friction step in its users’ workflow and automated it.
Integration With Adjacent Services Drives Retention
Rocket embedded mortgage into Redfin. Compass added title and escrow. Roofstock added property management. Standalone search tools lose users at the point of transaction. Platforms that handle what comes next keep them.
If your business needs a platform built around a specific workflow rather than adapted from an existing one, the process starts with how to build a real estate app before moving to development.
Final Thoughts
The top real estate apps on this list each solve a specific problem for a specific user. Zillow and Realtor.com serve residential search. Redfin and Compass serve buyers and agents with integrated workflows. Opendoor serves sellers who prioritize speed. Roofstock serves remote investors. Qarya and custom builds serve operators whose requirements no public app covers.
The right choice is the one that fits your actual workflow, not the platform with the most features or the biggest brand. A tool that solves the wrong problem wastes budget and creates workarounds that slow your team down.
If none of the platforms above fit what your business needs, the Hudasoft team can help you scope what a purpose-built solution would involve.

Frequently Asked Questions About The Top Real Estate Apps
What are the top real estate apps for buyers in 2026?
Zillow and Realtor.com are the two strongest options for residential buyers in 2026. Zillow covers 118 million properties with daily-updated Zestimate valuations, demand heat maps, and agent matching. Realtor.com pulls listings directly from MLS feeds, which makes its data more accurate for active listings. Redfin Powered by Rocket adds integrated mortgage preapproval and lower agent commissions for buyers who want search and financing in one platform.
Which real estate app has the most accurate listings?
Realtor.com has the most accurate residential listings among public portals because it pulls data directly from MLS feeds and is licensed by the National Association of Realtors. Zillow’s Zestimate has a median error rate of 1.74% for on-market homes but rises to 7.20% for off-market properties. For commercial listings, CREXi and Reonomy draw from proprietary transaction databases and public records, giving them stronger accuracy for commercial asset types than any residential portal.
What is the best real estate app for investors?
The answer depends on the investment type. For single-family rental investors, Roofstock provides vetted tenant-occupied properties with income data, cap rate projections, and property management options built in. For short-term rental investors, Mashvisor covers Airbnb occupancy rates and ADR by neighborhood. For commercial investors sourcing off-market deals, Reonomy provides ownership data and debt history across 50 million-plus commercial properties.
Is Zillow or Redfin better?
They serve different needs. Zillow has the largest residential database in the U.S. with 118 million properties and is stronger for browsing, Zestimate valuations, and neighborhood research. Redfin Powered by Rocket is stronger for buyers who want lower agent commissions, real-time MLS data, and integrated mortgage financing. In 2026, Redfin will also have access to Compass private exclusives not visible on Zillow, which matters in competitive markets. Most buyers benefit from using both rather than relying on one.
What real estate app do most realtors use?
Compass is the platform built specifically for agents, covering listings, client pipelines, deal tracking, predictive analytics, and title and escrow in one login. It reported 21,190 principal agents with a 96.8% quarterly retention rate in Q4 2025. However, Compass is only available to agents affiliated with the brokerage.
What is the best free real estate app?
Zillow, Redfin, Realtor.com, Trulia, and Redfin Data Center are all free for consumers. Among these, Zillow offers the broadest residential coverage, and Realtor.com offers the most MLS-accurate listings. Redfin Data Center is the strongest free resource for market trend data, publishing weekly updates on median prices, inventory levels, and days on market across 100-plus U.S. metros at no cost.
Which platforms provide the most comprehensive real estate listing analytics?
Zillow leads on residential listing analytics volume, covering 118 million properties with pricing history, demand heat maps, and days on market data. Realtor.com leads on MLS data accuracy for active listings. For commercial listing analytics, CREXi consolidates 153 million-plus property records and 84 million-plus sales comps. For investors needing off-market listing intelligence that MLS-connected platforms miss, PropStream adds distress signals, ownership data, and equity filters that no public portal provides.
When does building a custom real estate app make more sense than using an existing platform?
A custom platform makes sense when your workflow does not map onto any existing app’s data architecture. Specific signals include managing data across multiple asset classes that no single platform covers, running operations across disconnected tools that require manual reconciliation, or needing analytics embedded in your own client-facing product. Custom development through Hudasoft starts at $50,000 and scales based on scope and integrations. The decision point is whether the cost of workarounds in existing tools exceeds the build cost within 18 to 24 months.